
Projeye Giriş
Bu yazıda 102 farklı çiçek türünü belirlemek için nasıl derin bir öğrenme ağının kurulacağını göstereceğim. Bu yazıda, bu projeyi tamamlamak için PyTorch’u nasıl kullandığımı inceleyeceğim.
PyTorch ile derin öğrenme modelleri oluşturmada yeniyken, umarım bu gönderi bu derin öğrenme kitaplığını ilk kez kullananlara yardımcı olabilir.
Çok ileri gitmeden önce, üzerinde çalıştığımız verilere ve bu proje için klasör yapısının nasıl ayarlandığına bir göz atalım. Bu durumda kullanılan klasör yapısı, oluşturduğunuz her PyTorch modeli için klasörlerinizi nasıl ayarlamanız gerektiğidir
Proje türüne ve veri miktarına bağlı olarak, iki gruptan birini isteyeceksiniz:
– Train
– Test
Veya üç grup isteyebilirsiniz:
– Train
– Validation
– Test
Her dizinde, her sınıf için ayrı bir klasör isteyeceksiniz. Proje durumunda bu, 102 çiçek sınıfının her biri için ayrı bir klasör anlamına geliyordu. Her çiçek bir sayı olarak etiketlendi. Aşağıda, numaralandırılmış her bir dizinin bir dizi .jpg dosyası içerdiği klasör yapısı bulunmaktadır.

Çiçek türlerinin her biri için, eğitim veri kümesinde 27–206 görüntü, doğrulama veri kümesinde 1-28 görüntü ve test veri kümesinde 2-28 görüntü vardı.
Orijinal görüntüler 102 Kategori Çiçek Veri Kümesinden elde edildi ve yazarlar Maria-Elena Nilsback ve Andrew Zisserman tarafından şu şekilde açıklandı:
Görüntülerin büyük ölçekli, poz ve ışık varyasyonları vardır. Ek olarak, kategori içinde büyük varyasyonları olan kategoriler ve çok benzer birkaç kategori vardır. Veri kümesi, şekil ve renk özellikleriyle birlikte izomap kullanılarak görselleştirilir.
Her kategoride kaç tane görüntünün bulunduğunu elde etmek için aşağıdaki kabuk komutunun son derece yararlı olduğu kanıtlandı:
for dir in ./*/
do
ls ./${dir} -l . | egrep -c ‘^-‘
done
Çiçek türleri içindeki ve arasındaki değişkenlik hakkında fikir edinmek için farklı çiçek türlerinden birkaçına göz atalım.
Sınıflar arasında:

Sınıflar içinde:

Tüm çiçeklere ve buradaki bağlantıdaki veri setinde toplam kaç tane olduğuna bakabilirsiniz.
PyTorch’a Başlarken
İçindekiler
I. Veri Yükleme
II. Model Eğitimi
III. Model Testi
IV. Model Kontrol Noktasını Kaydet
V.Yük Modeli Kontrol Noktası
VI. Görüntüleri İşleme
VII. Sınıf Tahmini
VIII. Aklı kontrol
IX. Son düşünceler
X. Özel Teşekkürler
Veri Yükleme
Artık veri kümesi ve klasör yapısına aşina olduğumuza göre, PyTorch ile başlayabiliriz. Verileri okurken, PyTorch bunu jeneratörleri kullanarak yapar. Görüntü verileri büyük dosyalar oluşturma eğilimindedir, bu nedenle muhtemelen bu verileri bellekte saklamak istemezsiniz, bunun yerine anında oluşturmak istersiniz.
Belgeleri kullanmak, verilerinizi PyTorch için ayarlamak için gerçekten yararlı bazı ipuçları sağlar. Öncelikle, kütüphanelerimizin tamamını ayarlayalım. Nanodegree programının daha önceki bir bölümünden yola çıkarak, başlamak için iyi bir yer bulabiliriz. Gerekli olan yeni kütüphaneler buldukça bunu daha sonra güncelleyebiliriz.
%matplotlib inline
%config InlineBackend.figure_format = 'retina'import time
import json
import copyimport matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from PIL import Image
from collections import OrderedDictimport torch
from torch import nn, optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
from torchvision import datasets, models, transforms
Ardından, data_transformations’ınızı ayarlamak faydalıdır. Esasen, PyTorch’taki veri dönüşümleri, orijinal görüntülerin farklı şekillerde kırpılan veya farklı şekillerde döndürülen birçok varyasyonu üzerinde eğitim almamızı sağlar.
Nanodegree programının PyTorch bölümünde çalışırken, bunu yapmanın birkaç farklı yolunu öğrenirsiniz. Ancak, dokümantasyonun uyguladığım yöntem için özellikle yararlı olduğunu gördüm.
İlk olarak, her veri kümesi için veri dönüşümlerini ayarlamak istiyoruz. Genel olarak, veri doğrulama ve test setlerinde aynı tür dönüşümlere sahip olmak istiyoruz. Bununla birlikte, eğitim verileriyle, onu döndürülmüş, ters çevrilmiş ve kırpılmış görüntüler üzerinde eğiterek daha sağlam bir model oluşturabiliriz.
Ağımıza geçmeden önce görüntü değerlerini normalleştirmek için araçlar ve standart sapmalar sağlanmış olsa da, görüntü tensörlerinin farklı boyutlarının ortalama ve standart sapma değerlerine bakılarak da bulunabilirler.
data_transforms = {
‘train’: transforms.Compose([
transforms.RandomRotation(45),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
‘valid’: transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
‘test’: transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
}
ImageFolder ve DataLoader’ı kullanmak, görüntüleri gerekli dönüşümlerden ve ardından eğitim veya tahmin için ağımızdan kolayca geçirme becerisine izin verir. Bu gönderinin ilk bölümünde sağlanan klasör yapısı korunduğu sürece aşağıdaki kod kolayca azaltılabilir veya yeni örneklere genişletilebilir.
train_dir = 'train'
valid_dir = 'valid'
test_dir = 'test'dirs = {'train': train_dir,
'valid': valid_dir,
'test' : test_dir}image_datasets = {x: datasets.ImageFolder(dirs[x], transform=data_transforms[x]) for x in ['train', 'valid', 'test']}dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=32, shuffle=True) for x in ['train', 'valid', 'test']}dataset_sizes = {x: len(image_datasets[x])
for x in ['train', 'valid', 'test']}class_names = image_datasets['train'].classes
Ağımızı oluştururken ve eğitirken sonraki bölümlerde kullanılan yaratılan değişkenlerin her birini göreceksiniz.
Verilerimizi oluşturmanın son adımı olarak, etiket numarasından (1 ile 102 arasında bir sayı) ve gerçek çiçek adından bir eşleme oluşturmamız gerekiyordu. Udacity, bu eşleştirmenin sorunsuz bir şekilde yapılması için bir json dosyası sağlamıştır.
with open(‘flower_to_name.json’, ‘r’) as f:
label_map = json.load(f)
Transfer Öğrenimi
Son yıllarda, bilgisayarla görme problemlerinde yeniden kullanılmak üzere bir dizi model oluşturulmuştur. Bu önceden eğitilmiş modellerin kullanılması transfer öğrenimi olarak bilinir. PyTorch, önceden eğitilmiş modelleri yüklemeyi ve bunların üzerine inşa etmeyi kolaylaştırır, bu projede yapacağımız şeydir.
En popüler önceden eğitilmiş modellerden bazıları, tümü ImageNet Challenge’dan önceden eğitilmiş modeller olan VGGNet, ResNet ve AlexNet’i içerir. Bu önceden eğitilmiş modeller, başkalarının, ağırlıkları optimize etmek için doğru eğitim tekniğini bulmak için büyük miktarda hesaplama gücü, zaman ve sabra ihtiyaç duymadan bilgisayarla görmede en son sonuçları hızla elde etmesine olanak tanır.
Torchvision kütüphanesinden edinebileceğimiz vgg19 mimarisini kullanmaya karar verdim. Bununla birlikte, diğer modeller çok benzer bir kurulumla kolayca kullanılabilirdi.
model = models.vgg19(pretrained=True)
Modelin mimarisini basitçe çalıştırarak bile görebilirsiniz:
print(model)
Model mimarisinde gezinirseniz, birkaç evrişimli katmana sahip olduğunu fark edeceksiniz. Aşağıda ağın son katmanlarını görebilirsiniz.

Sınıflandırıcının tutarlı olması gereken iki bölümü vardır
- 25088 değerine sahip satırdaki (0) giriş özelliklerinin sayısı da ilk giriş katmanımızla aynı olmalıdır.
- Şu anda 1000 özellik olan satır (6) ‘daki çıktı özelliklerinin sayısı, veri setimizde sahip olduğumuz sınıfların sayısına eşit olmalıdır. Bizim durumumuzda, 102 çiçek sınıfını tahmin etmek isteyeceğiz.
Sorunumuzla tutarlı son katmanlar oluşturmak için, programda gösterilen iki yöntem vardı: bir sınıf oluşturmak veya sıralı bir sözlük kullanmak. İkincisini tercih ettim, bu nedenle ağımın bitiş katmanları aşağıdakilerle oluşturuldu:
classifier = nn.Sequential(OrderedDict([
(‘fc1’, nn.Linear(25088, 4096)),
(‘relu’, nn.ReLU()),
(‘fc2’, nn.Linear(4096, 102)),
(‘output’, nn.LogSoftmax(dim=1))
]))
Ardından, önceden eğitilmiş modelden ağırlıkları güncellememizi sağlar.
for param in model.parameters():
param.requires_grad = False
Vgg19’un sınıflandırıcı kısmını şu şekilde değiştirebiliriz:
model.classifier = classifier
Model Eğitimi
Artık modelimizi oluşturduğumuza göre, son katmanları eğitmek isteyeceğiz. Ayrıca ne kadar iyi çalıştığına dair bir fikir edinmek istiyoruz! Daha öncekiyle aynı belgelerden , modellerimizi eğitmek için bir işlev bulabiliriz. Burada gösterilen işlev, belgelerden neredeyse kelimesi kelimesine alınmıştır.
def train_model(model, criteria, optimizer, scheduler,
num_epochs=25, device='cuda'): since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
İlk argüman,modelönceki bölümde oluşturduğumuz modeldir.- İkinci argüman
criteria, model uyumunu değerlendirmek için kullanılan yöntemdir. optimizerAğırlıkları güncellemek için kullanılan optimizasyon tekniğidir.schedulerOptimizasyonu sırasında kullanılan öğrenme hızı ve adım boyutunu ayarlamaya ilişkin farklı yöntemler sağlar.epochDerslerde anlatıldığı gibi, ağ üzerinden ileri beslemesi ve geri yayılım dolu bir koşu.deviceOlarak ayarlandı'cuda'varsayılan olarak, ama sonra da ayarlı olabilir'cpu'yerel cpu (hayatının geri kalanı için) modeli eğitmek için isteseydim.
Modelimi eğitmek için yukarıdakileri aşağıdaki değerlere ayarlıyorum:
# Criteria NLLLoss which is recommended with Softmax final layer criteria = nn.NLLLoss() # Observe that all parameters are being optimized optim = optim.Adam(model.classifier.parameters(), lr=0.001) # Decay LR by a factor of 0.1 every 4 epochs sched = lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1) # Number of epochs eps=10
Udacity, modellerinizi eğitmek için sınıf GPU’larında zaman sağlar ve modelimi eğitmek için kullandığım işlev daha sonra aşağıda gösterildiği gibi belirtildi.
model_ft = train_model (model, ölçütler, optimizasyon, zamanlama, eps, ‘cuda’)
Her şey doğru ayarlanmışsa, aşağıdaki gibi bir şey görmelisiniz:
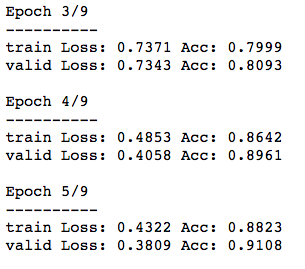
Bu umut verici görünüyor. Model her çağda öğreniyor gibi görünüyor.
Ek olarak, eğitim ve doğrulama ölçütleri çok fazla farklılaşmadığı için modelimiz aşırı uyumlu (en azından çok fazla) görünmüyor.
Ben sayısını değiştirerek bulundu epochs, optimizerve schedulerbenim sonuçları üzerinde en etkili olmuştur.
Tüm çiçek türlerinde yaklaşık % 91 doğrulama doğruluğuna sahip olan son sonuçlardan memnun olduğumda, test verilerinin doğruluğunu son bir kez kontrol edebilirdim.
Model Testi
Artık oldukça iyi olduğunu düşündüğüm bir modelim olduğuna göre, test verileri üzerinde ne kadar iyi çalışacağını test etmek istedim. Her bir test grubu için doğruluğu hızlı bir şekilde elde edebilmek için işlevi PyTorch belgelerinden basitleştirdim.
Önceden birkaç değişiklik fark edeceksiniz:
- Biz kullanmak
no_gradbu işlevle eğitmekle ilgilenen değil gibi. - Çıktı değerlerini elde etmek için, verilerimizi kullanarak tek bir ileri geçiş yapıyoruz
model.forward(inputs). Bununoutputs,LogSoftmaxher görüntü tahmini için modelden çıktı değerleri için 102 değerlik bir boyuta ve toplu işteki görüntülerin her biri için 32 değerlik başka bir boyuta sahip bir tensör olduğuna dikkat edin . Bunuprint(outputs)ve kullanarak görebilirsinizprint(outputs[0]). - Ardından
maxyöntemi kullanarak en olası görüntüyü elde edebiliriz. Spesifik olarak,LogSoftmaxher görüntü (içinde saklanan_) ve tahmin edilen görüntü etiketi (içinde saklanan) için maksimum değeri elde edersinizpredicted. - Ardından, tahmin edilen etiketin gerçek veri etiketiyle eşleşip eşleşmediğine bakabiliriz.
equalsTensör bir tutan1biz doğru tahmin eğer ve0biz yanlış tahmin eğer. - Son olarak, her partideki doğruluğu
1ve0değerlerinifloatdeğerlere dönüştürerek vemean.
def calc_accuracy(model, data, cuda=False):
model.eval()
model.to(device='cuda')
with torch.no_grad():
for idx, (inputs, labels) in enumerate(dataloaders[data]): if cuda:
inputs, labels = inputs.cuda(), labels.cuda() # obtain the outputs from the model
outputs = model.forward(inputs) # max provides the (maximum probability, max value)
_, predicted = outputs.max(dim=1) # check the
if idx == 0:
print(predicted) #the predicted class
print(torch.exp(_)) # the predicted probability
equals = predicted == labels.data if idx == 0:
print(equals) print(equals.float().mean())
Yukarıdakilere, printher adımda ne yapıldığını anlamama yardımcı olan bazı ifadeler de ekledim. Baskı ifadelerinin çıktısını burada görebilirsiniz:

32 resimlik bir toplu iş boyutuyla, her test görüntüsü için bir tahmin yapmak 26 grup aldı. Yukarıdaki görselde şunları görebilirsiniz:
- İlk tensördeki tahmin edilen çiçek türü.
- Modelin doğru çiçek türünü tahmin ettiğinden ne kadar emin olduğuyla ilişkili olasılık.
- Modelin gerçekten doğru olup olmadığı gerçeği.
- Her parti için doğruluk.
Partilerin doğruluğu 0.75 ile 1.0 arasında değişiyordu. Genel doğruluk, tüm partilerde yaklaşık 0,93 idi.
Model Kontrol Noktasını Kaydet
Doğru hiper parametreler dengesini elde etmeniz, modelinizi eğitmeniz ve bu noktaya gelmeniz muhtemelen biraz zaman aldı. PyTorch, bunu göz önünde bulundurarak, modellerinizi kontrol etme olanağını sağlar, böylece kaldığınız yerden kolayca devam edebilirsiniz.
Bu kodun kayda değer birkaç öğesi vardır:
torch.saveModelimizi gelecekte yeniden kullanmak üzere saklamak için kullanırız . Modelimizle ilgili her şeyi içindeki bir sözlükte saklamak yaygındırtorch.save.torch.saveBir sözlük ve sözlük nereye kaydedileceğini bir yolunu: Fonksiyon iki argüman alır.- Sözlüğümüzdeki ilk öğe, anahtar içinde kaydedilmiş kullandığım transfer öğrenme mimarisidir
arch. Bu gerçekten o kadar önemli değil, çünkü bunu yalnızca modelimi yüklerken bir if ifadesinde kullanacağım. Her biri farklı ağırlıklara sahip birçok temel modeliniz olsaydı, bu çok daha önemli olurdu. model.class_to_idxEndeksleri aslında bizim model tarafından tahmin edilmektedir çiçek endeksleri, çiçek sınıf değerlerinin Haritalamanız izler.label_mapÇiçek ismine çiçek sınıf geri eşleyebilirsiniz.

Bunu kafa karıştırıcı buldum, bu yüzden ilişkileri anlamanıza yardımcı olacak bir görsel bastım. Her sözlüğün anahtarları aynıdır.
Bu sözlüğü yaratmazsak, gelecekte bu modelle tahminlerde bulunduğumuzda gerçek çiçek etiketlerine geri dönmenin kolay bir yolunu bulamayız.
4. model.state_dict()Bir sözlükteki her katman için modelimizin tüm ağırlıklarını ve önyargılarını tutar. Gelecekte kullanmak üzere modelimizi yüklemek istediğimizde ihtiyacımız olan anahtar şey budur!
5. Tüm bu bilgiler bir dosyaya kaydedilir. Bu dosyadaki uzantı, topluluk için çok önemli görünmüyor. .pthPyTorch’un yaratıcısı tarafından önerilenleri gördüm , bu yüzden aşağıda kullandım. Ancak ben de .dat‘ı gördüm.
model.class_to_idx = image_datasets [‘train’]. class_to_idx
model.cpu ()
torch.save ({‘arch’: ‘vgg19’,
‘state_dict’: model.state_dict (),
‘class_to_idx’: model.class_to_idx},
‘ classifier.pth ‘)
Kaynak: https://medium.com/@josh_2774/deep-learning-with-pytorch-9574e74d17ad
