
Bir veri kümesinin temel yapısını nasıl buluyorsunuz? Bunu nasıl özetleyip en yararlı şekilde gruplandırıyorsunuz? Verileri sıkıştırılmış bir biçimde nasıl gösterirsiniz? Bunlar, “etiketsiz” olarak adlandırılan denetimsiz(gözetimsiz) öğrenmenin hedefleridir, çünkü etiketsiz verilerle başlarsınız (Y yoktur).
Araştıracağımız denetimsiz iki öğrenme görevi, veriyi benzerlik ve veriyi sıkıştırmak için yapısını ve yararlılığını koruyarak boyutsallığı azaltarak gruplar halinde kümelemektir.
Denetimli(Gözetimli) öğrenmenin aksine, denetlenmeyen bir öğrenme algoritmasının ne kadar iyi yaptığına ilişkin metrikler bulmak her zaman kolay değildir. “Performans” genellikle öznel ve alana özgüdür.
Kümeleme
Gerçek dünyada kümelemenin ilginç bir örneği, pazarlama veri sağlayıcısı Acxiom’un yaşam sahası kümeleme sistemi olan Personicx’tir. Bu hizmet, ABD’li aileleri, Facebook reklamlarını, görüntülü reklamları, doğrudan posta kampanyalarını vb. Hedefleyen reklamverenler tarafından kullanılan 21 yaşam aşaması grubundaki 70 ayrı kümeye bölünür.

Beyaz kâğıtları, her ikisi de bu bölümde ele alınan teknikler olan merkez kümelemesi ve temel bileşen analizi kullandıklarını ortaya koyuyor.
Bu kümelere erişmenin, (1) mevcut müşteri tabanlarını anlamalarını ve (2) potansiyel yeni müşterileri alakalı demografik, ilgi alanları ve yaşam tarzlarıyla hedefleyerek reklam harcamalarınızı etkili bir şekilde kullanmasını isteyen reklamverenler için son derece yararlı olduğunu düşünebilirsiniz.
Bu görevi nasıl yerine getirebileceğimize dair sezgileri geliştirmek için birkaç kümeleme yöntemi uygulayalım.
k-Means Kümeleme
“Ve k halkaları, her şeyin ötesinde, güç aramak üzere Centroid’lerin yarışına verildi.”
Kümelemenin amacı, farklı kümelerdeki noktalar benzer olmamakla birlikte bir küme içindeki noktalar benzer olacak şekilde veri noktaları grupları oluşturmaktır.
K-aracı kümeleme ile, veri noktalarımızı k gruplarına kümelemek istiyoruz. Daha büyük bir k, daha ayrıntılı olarak daha küçük gruplar, daha düşük bir k, daha büyük gruplar ve daha az taneli olma anlamına gelir.
Algoritmanın çıktısı, her veri noktasını k gruplarından birine atayan bir dizi “etiket” olacaktır. K-means kümelemesinde, bu grupların tanımlanma biçimi, her grup için bir merkez çizgisi yaratarak olur. Yüzdeler kümenin kalbi gibidir, kendilerine en yakın noktaları “yakalar” ve kümeye eklerler.
Bunları bir partiye katılan insanlar olarak düşünün ve çok dikkat çekici merkez olduklarından, çok manyetik oldukları için. Eğer bunlardan sadece bir tanesi varsa, herkes etrafında toplanır; Bir sürü varsa, daha küçük sayıda etkinlik merkezi oluşturulacaktır.
K-means kümelemesine ilişkin adımlar şunlardır:
1. K centroid’leri tanımlayın. Bunları rastgele olarak başlatınız(daha etkili bir şekilde yakınsaklaşan merkezlerin başlatılması için meraklı algoritmalar da vardır).
2. En yakın centroid ve güncelleme kümesi atamalarını bulun. Her veri noktasını k kümelerinden birine atayın. Her veri noktası en yakın centroid kümesine atanır. Burada, “yakınlık” ölçütü bir hiperparametre, genellikle Öklid mesafesidir.
3. Merkezleri kümelerin ortasına getirin. Her bir merkezin yeni konumu, kümesindeki tüm noktaların ortalama konumu olarak hesaplanır.
Her bir yinelemede(iterasyonda) ağırlık merkezi durana kadar (yani, algoritma yakınsamış oluncaya kadar) 2. ve 3. adımları tekrarlayın.
Bu, k-kümeleme’nin nasıl işlediğini verir! Algoritmanın bu görselleştirmesini kontrol edin – bir çizgi roman gibi okuyun. Uçaktaki her nokta, her anında en yakın olan centroid’e göre renklidir. Centroidlerin (daha büyük mavi, kırmızı ve yeşil daireler) rastgele başlayıp ardından kendi kümelerini yakalamak için çabucak ayarlandığını fark edeceksiniz.

K-aracı kümelemesinin bir başka gerçek hayat uygulaması, el yazısı basamaklarını sınıflandırmaktır. Piksel parlaklıklarının uzun bir vektörü olarak rakamlardan oluşan görüntülerimiz olduğunu varsayalım. Diyelim ki görüntüler siyah beyaz ve 64×64 pikseldir. Her piksel bir boyutu temsil eder. Dolayısıyla bu görüntülerin yaşadığı dünya 64×64 = 4.096 boyutundadır. Bu 4,096 boyutlu dünyada, k-aracı kümeleme, birbirine yakın görüntüleri gruplamamızı ve rakam tanıma için oldukça iyi sonuçlar elde edebilen aynı haneyi temsil ettiklerini varsaymamızı sağlar.
Hiyerarşik Kümeleme
“Bir milyon seçeneği yedi seçenek haline getirelim. Ya da beş. Ya da yirmi? Eh, belki sonra karar verebiliriz.”
Hiyerarşik kümeleme, kümelenmelerin bir hiyerarşisini oluşturmayı hedeflemeniz dışında, normal kümelemeye benzer. Bu, sonunda istediğiniz sayıda kümede esneklik istediğinizde yararlı olabilir. Örneğin, öğeleri Etsy veya Amazon gibi bir çevrimiçi pazarda gruplandırmayı hayal edin. Ana sayfada, basit gezinme için birkaç geniş kategori öğesi olmasını istersiniz. Ancak, daha spesifik alışveriş kategorilerine girdiğinizde, daha fazla ayrıntı düzeyini, yani daha farklı öğe kümeleri olmasını istersiniz.
Algoritma çıktıları açısından, küme atamalarına ek olarak, kümeler arasındaki hiyerarşileri anlatan güzel bir ağaç da oluşturabilirsiniz. Daha sonra bu ağaçtan istediğiniz küme sayısını seçebilirsiniz.
Hiyerarşik kümeleme için adımlar şunlardır:
1. Her veri noktası için bir tane olan N kümeleriyle başlayın.
2. Birbirine en yakın olan iki kümeyi birleştirin. Şimdi N-1 kümeleriniz var.
3. Kümeler arasındaki mesafeleri yeniden hesaplayın. Bunu yapmanın birkaç yolu vardır. Bunlardan biri, iki kümenin arasındaki mesafeyi, ilgili tüm üyeler arasındaki ortalama mesafe olarak düşünmektir.
4. Bir küme N veri noktası elde edene kadar 2. ve 3. adımları tekrarlayın. Aşağıdaki gibi bir ağaç(bir dendrogram olarak da bilinir) elde edersiniz.
5. Bir dizi küme seçin ve dendrogramda yatay bir çizgi çizin. Örneğin, k = 2 kümelerini istiyorsanız, “distance = 20000” etrafında yatay bir çizgi çizmeniz gerekir. Veri noktaları 8, 9, 11, 16 ve veri kümelerinin geri kalanı ile bir küme elde edeceksiniz. . Genel olarak, aldığınız kümelerin sayısı, yatay çizginizin kesişim noktalarının sayısı dendrogramdaki dikey çizgilerdir.

Boyutsal Küçülme
Boyutsallık azaltma, sıkıştırma gibi çok şey ifade eder. Bu, ilgili yapıyı olabildiğince çok tutarken, verilerin karmaşıklığını azaltmaya çalışmakla ilgilidir. Basit bir 128 x 128 x 3 piksel görüntü (uzunluk x genişlik x RGB değeri) alırsanız, bu 49.152 veri boyutudur. Bu görüntülerin, görüntülerde çok fazla anlamlı içeriği yok etmeden yaşadığı alanın boyutsallığını azaltabiliyorsanız, boyutsal indirgemede iyi bir iş çıkarmış olursunuz.
Pratikte iki yaygın tekniğe bir göz atacağız: temel bileşen analizi ve tekil değer ayrıştırması.
Temel Bileşen Analizi (PCA)
Öncelikle, biraz lineer cebir tazeleme – boşluklar ve üsler hakkında konuşalım.
Koordinat düzlemini orijin O (0,0) ve temel vektörler i (1,0) ve j (0,1) ile biliyorsunuzdur. Tamamen farklı bir temel seçebiliyorsunuz ve hala tüm matematik çalışmalarınız var. Örneğin, O karakterini kaynak olarak tutabilir ve i ‘= (2,1) ve j ’= (1,2) vektörlerini temelleyebilirsiniz. Sabrınız varsa, i ‘, j’ koordinat sistemindeki (2,2) i noktasının i, j sisteminde etiketlendiğini (6, 6) kendinize ikna edersiniz.

Bu, bir alanın temelini değiştirebileceğimiz anlamına gelir. Şimdi çok daha yüksek boyutlu bir alan hayal edin. 50K ölçüleri gibi. Bu alan için bir temel seçebilir ve ardından bu temelin yalnızca 200 en önemli vektörünü seçebilirsiniz. Bu temel vektörlere temel bileşenler denir ve seçtiğiniz alt grup, boyutsallıkta orijinal alandan daha küçük olan ancak mümkün olduğunca verilerin karmaşıklığını koruyan yeni bir alan oluşturur.
En önemli temel bileşenleri seçmek için, verilerin varyasyonunun ne kadarını ele geçirdiğine bakarız ve bunları bu metrikle sıralarız.
Bunu düşünmenin başka bir yolu, PCA’nın, verilerin daha sıkıştırılabilir hale gelmesi için var olan alanı yeniden ele geçirmesidir. Dönüştürülen boyut orijinal boyuttan daha küçüktür.
Yalnızca yeniden eşlenen alanın ilk birkaç boyutundan yararlanarak, veri kümesinin kuruluşunun bir anlayışını kazanmaya başlayabiliriz. Bu boyutsal indirgeme vaadi: yapıyı korurken (varyans) karmaşıklığı (bu durumda boyutsallığı) azaltın. İşte Samer, Wikileaks kablo yayınını anlamayı denemek için PCA’yı (ve difüzyon eşlemesi, başka bir teknik) kullanarak yazdı.
Tekil Değer Ayrıştırması (SVD)
Verilerimizi büyük bir A = m x n matrisi gibi temsil edelim. Tekil değer ayrıştırması, bu büyük matrisin 3 küçük matrisin bir ürününe (U = m x r, diyagonal matris Σ = r x r ve V = r x n burada r küçük bir sayıdır.) ayrılmasına olanak veren bir hesaplamadır.
Buradan başlayacağınız daha görsel bir resim:

R * r köşegen matrisindeki değerler tekil değer olarak adlandırılır. Bunlar hakkında güzel olan, bu tekil değerlerin orijinal matrisi sıkıştırmak için kullanılabileceğidir. Tekil değerlerin en küçük %20’sini ve U ve V matrislerindeki ilişkili sütunlara bırakırsanız, oldukça az yer kaplar ve yine de temel matrisin iyi bir temsilini elde edersiniz.
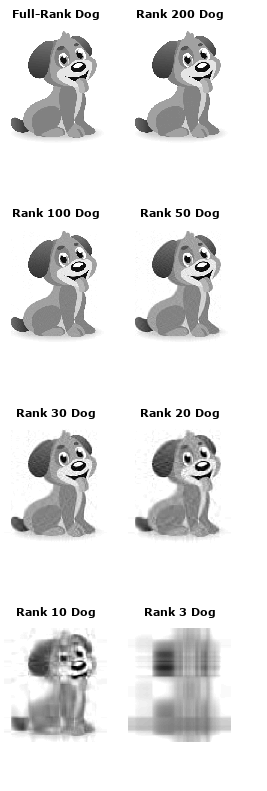
Bunun daha net bir şekilde ne olduğunu incelemek için bir köpeğin bu görüntüsüyle çalışalım:

Andrew Gibiansky’nin SVD’de yayınladığı kodu kullanacağız. İlk olarak, tekil değerlerin (matris values) büyüklüklerine göre sıralanması halinde, ilk 50 tekil değerlerin tüm matrisin 85 büyüklüğünün %85’ini içerdiğini gösteriyoruz.
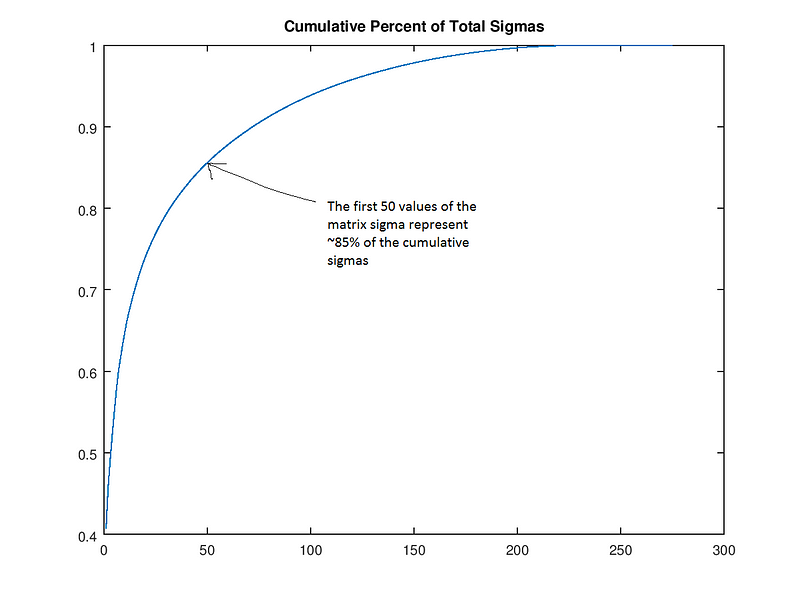
Bu gerçeği Σ(sigma)’nın sonraki 250 değerini atmak için kullanabiliriz (yani, onları 0’a ayarlayabiliriz) ve sadece köpeğin görüntüsünün “rütbe(rank) 50” versiyonunu saklayabiliriz. Burada, 200, 100, 50, 30, 20, 10 ve 3 numaralı bir köpek yaratıyoruz. Açıkçası, resim daha küçüktür, ancak rank-30 köpeğin hala iyi olduğunu kabul edelim. Şimdi bu köpekle ne kadar sıkıştırma yaptığımızı görelim. Orijinal görüntü matrisi 305 * 275 = 83.875 değerdir. 30 köpek 305 * 30 + 30 + 30 * 275 = 17.430 – görüntü kalitesinde çok az kayıp ile neredeyse 5 kat daha az değer. Yukarıdaki hesaplamanın nedeni, UΣ’V işlemi gerçekleştirildiğinde sıfırlar ile çarpılan U ve V matrisinin parçalarını da atmamızdır (burada Σ’, Σ nın değiştirilmiş sürümü olup, içinde sadece ilk 30 değeri vardır).
Denetimsiz öğrenme genellikle verileri önceden işlemek için kullanılır. Genellikle, bu, derin bir sinir ağıyla ya da başka bir denetimli öğrenme algoritmasıyla beslenmeden önce PCA ya da SVD ile olduğu gibi bir anlamda koruma tarzında sıkıştırmak anlamına gelir.
Örnek bir uygulama yapalım;
# Kütüphanelerimizi yükleyelim.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Verimizi oluşturalım.
df = pd.DataFrame({
‘x’: [29, 33, 24, 45, 45, 52],
‘y’: [39, 36, 30, 52, 54, 46]
})
#x ve y datası 2 kümeye ayrılır ve grafiği çizdirilir.
np.random.seed(100)
k = 2
# centroids[i] = [x, y]
centroids = {
i+1: [np.random.randint(0, 80), np.random.randint(0, 80)] #0-80 arası rastgele 2yer belirler.
for i in range(k)
}
fig = plt.figure(figsize=(5, 5))
plt.scatter(df[‘x’], df[‘y’], color=’k’)
colmap = {1: ‘r’, 2: ‘g’, 3: ‘b’}
for i in centroids.keys():
plt.scatter(*centroids[i], color=colmap[i])
plt.xlim(0, 60)
plt.ylim(0, 60)
plt.show()

# Merkeze uzaklık hesaplanır(x ve y kümenin ağırlık merkezinden çıkarılır.)
def assignment(df, centroids):
for i in centroids.keys():
# sqrt((x1 – x2)^2 – (y1 – y2)^2)
df[‘distance_from_{}’.format(i)] = (
np.sqrt(
(df[‘x’] – centroids[i][0]) ** 2
+ (df[‘y’] – centroids[i][1]) ** 2
)
)
centroid_distance_cols = [‘distance_from_{}’.format(i) for i in centroids.keys()]
df[‘closest’] = df.loc[:, centroid_distance_cols].idxmin(axis=1)
df[‘closest’] = df[‘closest’].map(lambda x: int(x.lstrip(‘distance_from_’)))
df[‘color’] = df[‘closest’].map(lambda x: colmap[x])
return df
df = assignment(df, centroids)
print(df.head())
fig = plt.figure(figsize=(5, 5))
plt.scatter(df[‘x’], df[‘y’], color=df[‘color’], alpha=0.5, edgecolor=’k’)
for i in centroids.keys():
plt.scatter(*centroids[i], color=colmap[i])
plt.xlim(0, 60)
plt.ylim(0, 60)
plt.show()

import copy
old_centroids = copy.deepcopy(centroids)
def update(k):
for i in centroids.keys():
centroids[i][0] = np.mean(df[df[‘closest’] == i][‘x’])
centroids[i][1] = np.mean(df[df[‘closest’] == i][‘y’])
return k
centroids = update(centroids)
fig = plt.figure(figsize=(5, 5))
ax = plt.axes()
plt.scatter(df[‘x’], df[‘y’], color=df[‘color’], alpha=0.5, edgecolor=’k’)
for i in centroids.keys():
plt.scatter(*centroids[i], color=colmap[i])
plt.xlim(0, 60)
plt.ylim(0, 60)
for i in old_centroids.keys():
old_x = old_centroids[i][0]
old_y = old_centroids[i][1]
dx = (centroids[i][0] – old_centroids[i][0]) * 0.75
dy = (centroids[i][1] – old_centroids[i][1]) * 0.75
ax.arrow(old_x, old_y, dx, dy, head_width=2, head_length=3, fc=colmap[i], ec=colmap[i])
plt.show()
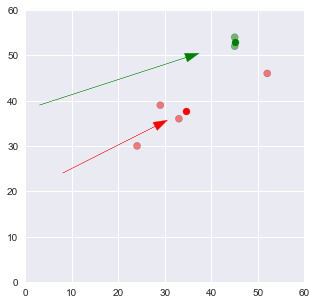
df = assignment(df, centroids)
# Sonuçları çizdirelim.
fig = plt.figure(figsize=(5, 5))
plt.scatter(df[‘x’], df[‘y’], color=df[‘color’], alpha=0.5, edgecolor=’k’)
for i in centroids.keys():
plt.scatter(*centroids[i], color=colmap[i])
plt.xlim(0, 60)
plt.ylim(0, 60)
plt.show()

while True:
closest_centroids = df[‘closest’].copy(deep=True)
centroids = update(centroids)
df = assignment(df, centroids)
if closest_centroids.equals(df[‘closest’]):
break
fig = plt.figure(figsize=(5, 5))
plt.scatter(df[‘x’], df[‘y’], color=df[‘color’], alpha=0.5, edgecolor=’k’)
for i in centroids.keys():
plt.scatter(*centroids[i], color=colmap[i])
plt.xlim(0, 60)
plt.ylim(0, 60)
plt.show()

Böylece verileri 2 kümeye ayırdık ve bu kümelerin merkezini bulmuş olduk.
Uygulama materyalleri ve daha fazla okuma
3a – k-means kümeleme
Algoritmanın nasıl çalıştığına dair sezgiler oluşturmak için bu kümeleme görselleştirmesi ile oynayın. Ardından, el yazısıyla yazılmış rakamlar ve ilişkili eğitici için k-aracı kümeleme uygulamasına bir göz atın.
3b – tekil değer ayrıştırması
SVD hakkında iyi bir referans için, Andrew Gibiansky’nin yayınından başka bir yere gitmeyin.
Kaynak: https://medium.com/machine-learning-for-humans/unsupervised-learning-f45587588294

One thought on “Denetimsiz Öğrenme Yöntemleri”